理论#
MapReduce 主要用来解决大规模数据处理的问题,它能够将一个计算任务分解为许多小任务,这些小任务可以在多台机器上并行执行,从而大大提高处理速度和效率。
它的核心思想参考 Google 论文中的图片
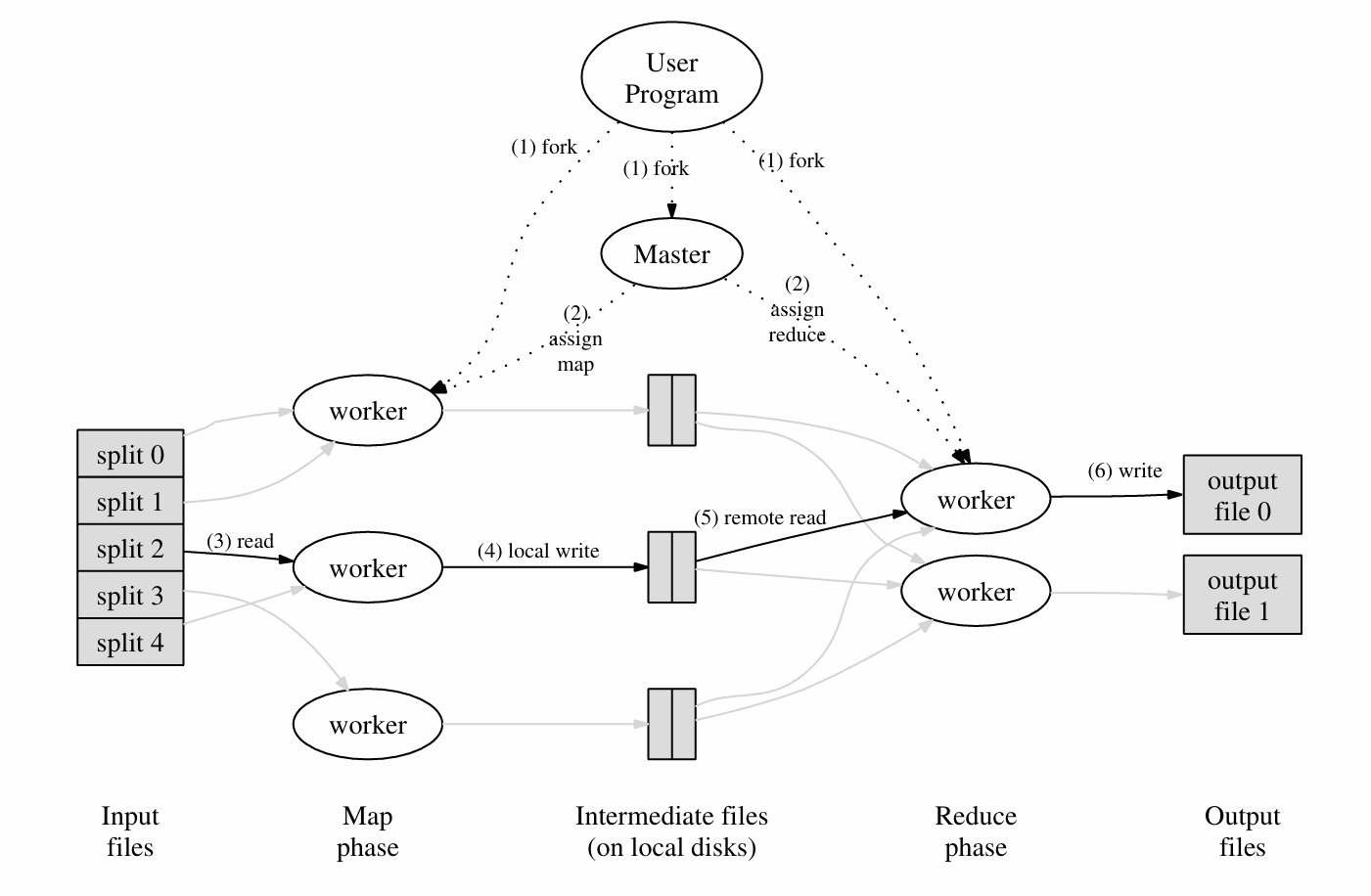
Master 程序是主要的程序,它会将文件(N 个)分配个 worker,所有 worker 是对等的。worker 将会首先执行 Map 命令,接受一些文件,然后输出为键值对并写入 R 个(用户可以自定义 R 的值)中间文件(图中的 Intermediate files)。当所有 Map 任务完成后,Master 会给 worker 分配 Reduce 任务,对中间文件进行处理,然后生成最终的结果文件。
其中,Map 函数和 Reduce 函数可以以插件的形式提供给系统。
例如,在 Words Count 场景下(统计若干文件里每个相同单词的数量):
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
这个例子中,map 函数将生成一系列 key 为 word,value 为 "1" 的中间文件,然后 reduce 将同一个 key 聚合,统计 value 的数量。
这样我们就实现了数据集的分布式处理。
代码#
系统的启动流程如下:
- 运行mrcoordinator
- 运行若干个 mrworker
- mrcoordinator 调用 coordinator,并定期检查 coordinator 完成情况
- mrworker 加载 map 和 reduce 函数,并拉起 worker 进程
其中 coordinator 和 worker 之间使用 rpc 通信,我们只需要实现 coordinator 和 worker 的逻辑。
Coordinator#
几个要点:
- 考虑维护 task 的状态,而不需要维护 worker 的状态,因为 worker 实际上是对等的。
- Coordinator 是多线程的,需要加锁。由于不需要各线程通信,这里选用 Mutex
- 两个 rpc 关键函数:FetchTask 和 FinishTask,一个用来给 worker 查找任务,一个用来标记任务结束
关键结构体如下:
type Coordinator struct {
// Your definitions here.
lock sync.Mutex
files []string
mapTaskStatuses []int
reduceTaskStatuses []int
nMap int
nReduce int
mapDoneNum int // map任务完成数量
reduceDoneNum int
mapFinished bool
reduceFinished bool
}
两个 rpc 函数主要逻辑:
func (c *Coordinator) FetchTask(args *FetchTaskArgs, reply *FetchTaskReply) error {
c.lock.Lock()
defer c.lock.Unlock()
if !c.mapFinished {
mapNum := xxx // 循环mapTaskStatuses找到未开始的任务
if mapTaskStatuses全都分配了 {
reply.TaskType = NOTASK
} else {
// 分配任务
// 10s不完成任务就错误恢复
}
} else if !c.reduceFinished {
// 和map类似
}
} else {
reply.TaskType = NOTASK
}
return nil
}
func (c *Coordinator) FinishTask(args *FinishTaskArgs, reply *FinishTaskReply) error {
c.lock.Lock()
defer c.lock.Unlock()
switch args.TaskType {
case MAPTASK:
{
// 由于错误恢复机制,这里可能提交同样的任务。仅接受第一个提交的任务即可
if c.mapTaskStatuses[args.TaskNum] != DONE {
c.mapDoneNum += 1
c.mapTaskStatuses[args.TaskNum] = DONE
if c.mapDoneNum == c.nMap {
c.mapFinished = true
}
}
}
case REDUCETASK:
// 和上面类似
}
return nil
}
Worker#
worker 主要是业务逻辑。大体框架如下:
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
for {
reply := &FetchTaskReply{}
ok := call("Coordinator.FetchTask", &FetchTaskArgs{}, &reply)
if ok {
switch reply.TaskType {
case MAPTASK:
{
// 根据reply指定的filename调用map处理,并输出中间文件
// rpc FinishTask
}
case REDUCETASK:
{
// 根据reply的ReduceNum读取中间文件(多个),输出为一个结果文件
mp := make(map[string][]string)
// 聚合
// reduce
// rpc FinishTask
}
case NOTASK:
{
break
}
}
} else {
break
}
}
}
一些细节需要注意:
- 中间文件名为mr-X-Y,X 是 MapNum(即 map 任务编号),Y 是 map 函数生成的 key 到 [0, NReduce) 整数集的单射,具体而言是通过如下哈希函数计算的:
func ihash(key string) int {
h := fnv.New32a()
h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
- 每一个 reduce 函数需要处理一个 Y 对应的所有 X
- 由于 reduce 的输入是一个 key 和它对应的所有 values,所以需要对中间文件进行聚合。这里使用的是 HashMap。在生产级别的 MapReduce 实现中,该部分需要内存 + 外存来保证不会 OOM。
- 为了保证创建并写入文件的原子性(要么完全写入,要么完全不写入),可以先创建临时文件,再写入,再重命名:
func writeStringToFileAtomic(filename string, content string) {
f, _ := os.CreateTemp(".", filename+"*")
f.WriteString(content)
os.Rename(f.Name(), filename)
f.Close()
}
- reduce 最后生成的文件内容需要不断拼接结果字符串,应该使用 StringBuilder 来获得更好的性能
var result strings.Builder
for key, values := range mp {
reduceResult := reducef(key, values)
result.WriteString(fmt.Sprintf("%v %v\n", key, reduceResult))
}
// 获得字符串:result.String()
拓展#
重读 Google 的论文可以发现 Google 用于生产环境的 MapReduce 相比于我们上面实现的 lab 还有几个改进:
- 当 worker 运行在多个机器上时,需要使用一些分布式文件系统方案来管理文件,例如 GFS
- reduce 生成的文件可能会被用于下一个 MapReduce 任务,从而形成某种链子
- 在实际实现中,还是需要维护 Worker 的状态,这样可以便于获取 Worker 机器的信息、错误恢复等
- 实际使用中,Google 发现当一些机器在即将处理完 Map 或 Reduce 任务时,性能会出现明显的下降。解决方法是 Master 在组任务即将完成时会分配剩下的任务作为 Backup Tasks,分配到其他 worker 上,以最快完成的任务为最终结果。
Google 也提出了一些改进思路
- Partitioning Function:上面把 key 映射的 hash 函数是可以自定义的,叫做 Partitioning Function。例如 key 是 URL 的时候可以把同一个 Host 分到同一个 Reduce 任务里
- Ordering Guarantees:在同一个 partition 里可以先做 key 的排序处理,这样可以使得结果更为友好
- Combiner Function:注意到上面 Words Count 例子中,大量的类似 (word,"1") 会在网络上传输,而根据 key 聚合 values 发生在 reduce 函数中。如果把聚合操作写在 map 函数里则可以避免这些重复的数据传输。combiner function 和 reduce function 的唯一区别是前者输出中间文件,后者输出最终文件。
- Input and Output Types:Google 提供了 reader 接口,使得用户在实现 Map 函数的时候可以读取更多的 Input Types,例如数据库里的数据或内存里的数据。Output 同理。
- master 可以维护一个 HTTP panel 显示各个 worker、task 等的状态
- Counter:可以在 map 函数调用自定义的 counter,持续返回给 master。者可以用于收集一些数据的信息,例如 Words Count 例子中
Counter* uppercase;
uppercase = GetCounter("uppercase");
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, "1");
最后,2024 年的今天 MapReduce 对于 Google 来说早已经成为了历史。但是它催生出了 Hadoop 等开源大数据处理框架。