Theory#
MapReduce is mainly used to solve the problem of large-scale data processing. It can decompose a computational task into many smaller tasks that can be executed in parallel on multiple machines, greatly improving processing speed and efficiency.
Its core idea refers to the image in the Google paper.
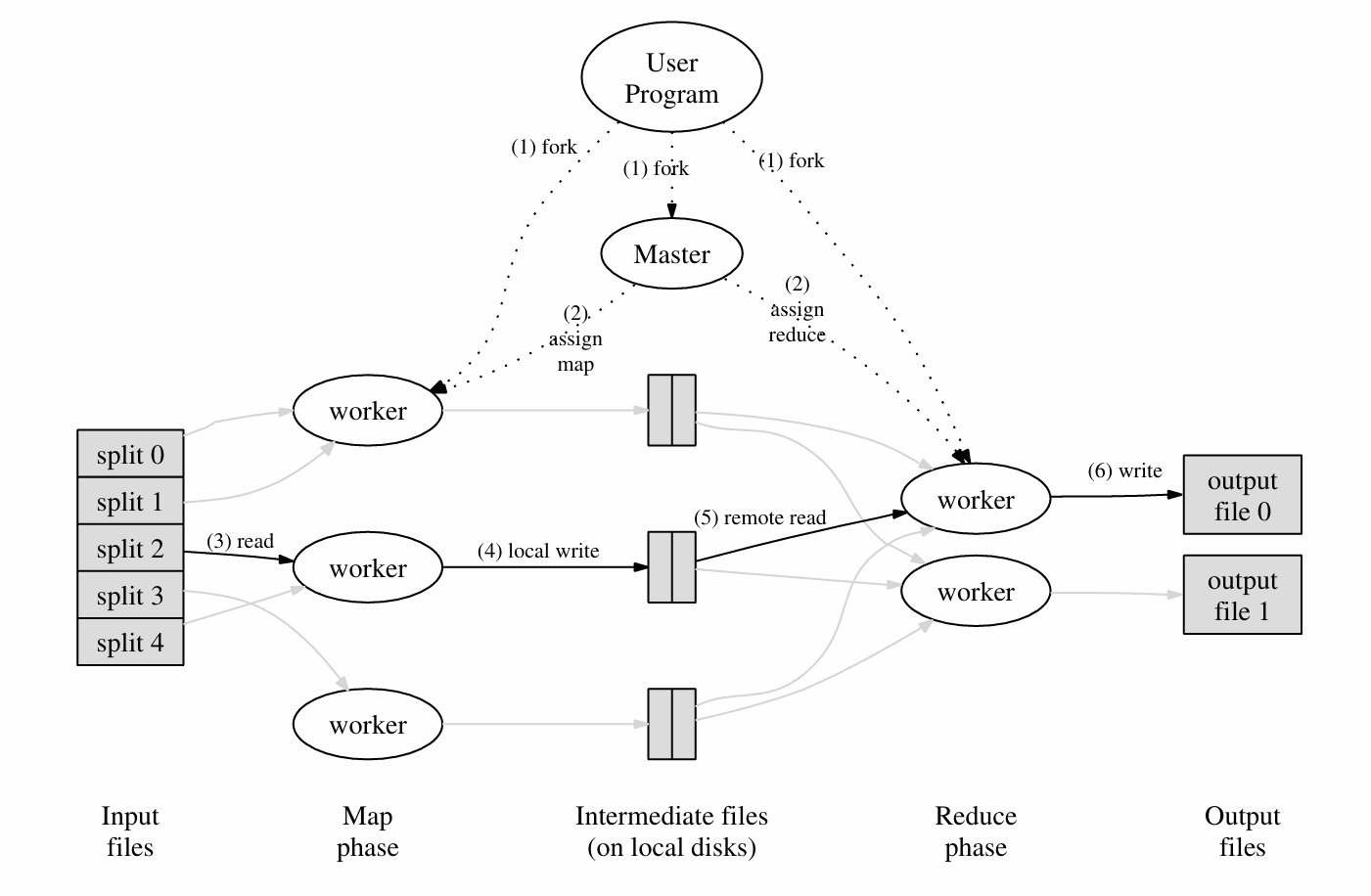
The Master program is the main program that assigns files (N files) to workers, where all workers are peers. The worker will first execute the Map command, accept some files, and then output key-value pairs and write them into R (the user can customize the value of R) intermediate files (the Intermediate files in the image). When all Map tasks are completed, the Master will assign Reduce tasks to the workers to process the intermediate files and then generate the final result file.
The Map and Reduce functions can be provided to the system in the form of plugins.
For example, in the Words Count scenario (counting the number of occurrences of each identical word in several files):
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
In this example, the map function generates a series of intermediate files with keys as words and values as "1", and then the reduce function aggregates the same keys to count the number of values.
Thus, we achieve distributed processing of the dataset.
Code#
The system startup process is as follows:
- Run mrcoordinator
- Run several mrworkers
- mrcoordinator calls the coordinator and periodically checks the completion status of the coordinator
- mrworker loads map and reduce functions and starts the worker process
The communication between the coordinator and worker uses RPC, and we only need to implement the logic for the coordinator and worker.
Coordinator#
Key points:
- Consider maintaining the state of tasks without needing to maintain the state of workers, as workers are actually peers.
- The Coordinator is multi-threaded and requires locking. Since there is no need for communication between threads, Mutex is chosen here.
- Two key RPC functions: FetchTask and FinishTask, one for the worker to find tasks, and one to mark the task as complete
The key structure is as follows:
type Coordinator struct {
// Your definitions here.
lock sync.Mutex
files []string
mapTaskStatuses []int
reduceTaskStatuses []int
nMap int
nReduce int
mapDoneNum int // number of completed map tasks
reduceDoneNum int
mapFinished bool
reduceFinished bool
}
The main logic of the two RPC functions:
func (c *Coordinator) FetchTask(args *FetchTaskArgs, reply *FetchTaskReply) error {
c.lock.Lock()
defer c.lock.Unlock()
if !c.mapFinished {
mapNum := xxx // Loop through mapTaskStatuses to find unstarted tasks
if all mapTaskStatuses are allocated {
reply.TaskType = NOTASK
} else {
// Allocate task
// Error recovery if task is not completed in 10s
}
} else if !c.reduceFinished {
// Similar to map
}
} else {
reply.TaskType = NOTASK
}
return nil
}
func (c *Coordinator) FinishTask(args *FinishTaskArgs, reply *FinishTaskReply) error {
c.lock.Lock()
defer c.lock.Unlock()
switch args.TaskType {
case MAPTASK:
{
// Due to the error recovery mechanism, the same task may be submitted here. Only accept the first submitted task.
if c.mapTaskStatuses[args.TaskNum] != DONE {
c.mapDoneNum += 1
c.mapTaskStatuses[args.TaskNum] = DONE
if c.mapDoneNum == c.nMap {
c.mapFinished = true
}
}
}
case REDUCETASK:
// Similar to above
}
return nil
}
Worker#
The worker mainly handles business logic. The general framework is as follows:
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
for {
reply := &FetchTaskReply{}
ok := call("Coordinator.FetchTask", &FetchTaskArgs{}, &reply)
if ok {
switch reply.TaskType {
case MAPTASK:
{
// Call map processing based on the filename specified in reply and output intermediate files
// RPC FinishTask
}
case REDUCETASK:
{
// Read intermediate files (multiple) based on reply's ReduceNum and output to a result file
mp := make(map[string][]string)
// Aggregate
// Reduce
// RPC FinishTask
}
case NOTASK:
{
break
}
}
} else {
break
}
}
}
Some details to note:
- The intermediate file name is mr-X-Y, where X is MapNum (i.e., the map task number), and Y is the one-to-one mapping of keys generated by the map function to the integer set [0, NReduce), specifically calculated using the following hash function:
func ihash(key string) int {
h := fnv.New32a()
h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
- Each reduce function needs to handle all X corresponding to a Y.
- Since the input to reduce is a key and all its corresponding values, it is necessary to aggregate the intermediate files. A HashMap is used here. In a production-level MapReduce implementation, this part requires both memory and external storage to avoid OOM.
- To ensure the atomicity of file creation and writing (either fully written or not written at all), you can first create a temporary file, then write to it, and then rename it:
func writeStringToFileAtomic(filename string, content string) {
f, _ := os.CreateTemp(".", filename+"*")
f.WriteString(content)
os.Rename(f.Name(), filename)
f.Close()
}
- The final file content generated by reduce needs to continuously concatenate result strings, and StringBuilder should be used for better performance.
var result strings.Builder
for key, values := range mp {
reduceResult := reducef(key, values)
result.WriteString(fmt.Sprintf("%v %v\n", key, reduceResult))
}
// Get the string: result.String()
Expansion#
Re-reading Google's paper reveals that the MapReduce used in Google's production environment has several improvements compared to the lab implementation above:
- When workers run on multiple machines, some distributed file system solutions need to be used to manage files, such as GFS.
- The files generated by reduce may be used for the next MapReduce task, forming a kind of chain.
- In actual implementation, it is still necessary to maintain the state of workers to facilitate obtaining information about worker machines, error recovery, etc.
- In practical use, Google found that when some machines are about to finish Map or Reduce tasks, performance can significantly decline. The solution is that the Master will allocate the remaining tasks as Backup Tasks to other workers when the group tasks are about to complete, with the fastest completed task being the final result.
Google also proposed some improvement ideas.
- Partitioning Function: The hash function that maps keys can be customized, called the Partitioning Function. For example, when the key is a URL, the same Host can be assigned to the same Reduce task.
- Ordering Guarantees: Sorting can be performed on keys within the same partition, making the results more user-friendly.
- Combiner Function: Noticing that in the above Words Count example, a large number of similar (word, "1") pairs are transmitted over the network, and the aggregation of values occurs in the reduce function. If the aggregation operation is written in the map function, it can avoid these duplicate data transmissions. The only difference between the combiner function and the reduce function is that the former outputs intermediate files while the latter outputs final files.
- Input and Output Types: Google provides a reader interface, allowing users to read more Input Types when implementing the Map function, such as data from databases or memory. The same applies to Output.
- The master can maintain an HTTP panel displaying the status of various workers, tasks, etc.
- Counter: Custom counters can be called in the map function, continuously returning to the master. This can be used to collect information about some data, such as in the Words Count example.
Counter* uppercase;
uppercase = GetCounter("uppercase");
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, "1");
Finally, as of today in 2024, MapReduce has long become history for Google. However, it has given rise to open-source big data processing frameworks like Hadoop.